Idk, I never used the weird advanced features of YAML, but the basics seems really nice for stuff you want people, especially non programmers, to edit. I generally default to YAML for config files.
XML is ok for complex docs where you have a detailed structure and relationships. JSON is good for simple objects. YAML is good for being something to switch to for the illusion of progress.
Meh. I just wish XML was easier to parse. I have to shuttle a lot of XML data back and forth. As far as I can tell, the only way to query the data is to download a whole engine to run a special query language, and that doesn’t really integrate into any of my workflows. JSON retains the hierarchy and is trivially parsed in almost any programming language. I bet a JSON file containing the exact same data would be much smaller also, since you don’t list each tag twice.
XML is also tricky to parse because people forget it is for documents too. It’s basically like HTML. Mixed content elements are allowed. <foo>hey <bar>there</bar> friend</foo> is valid XML. So iterating over elements is trickier than JSON (which is just key value pairs and arrays).

{kind=link}
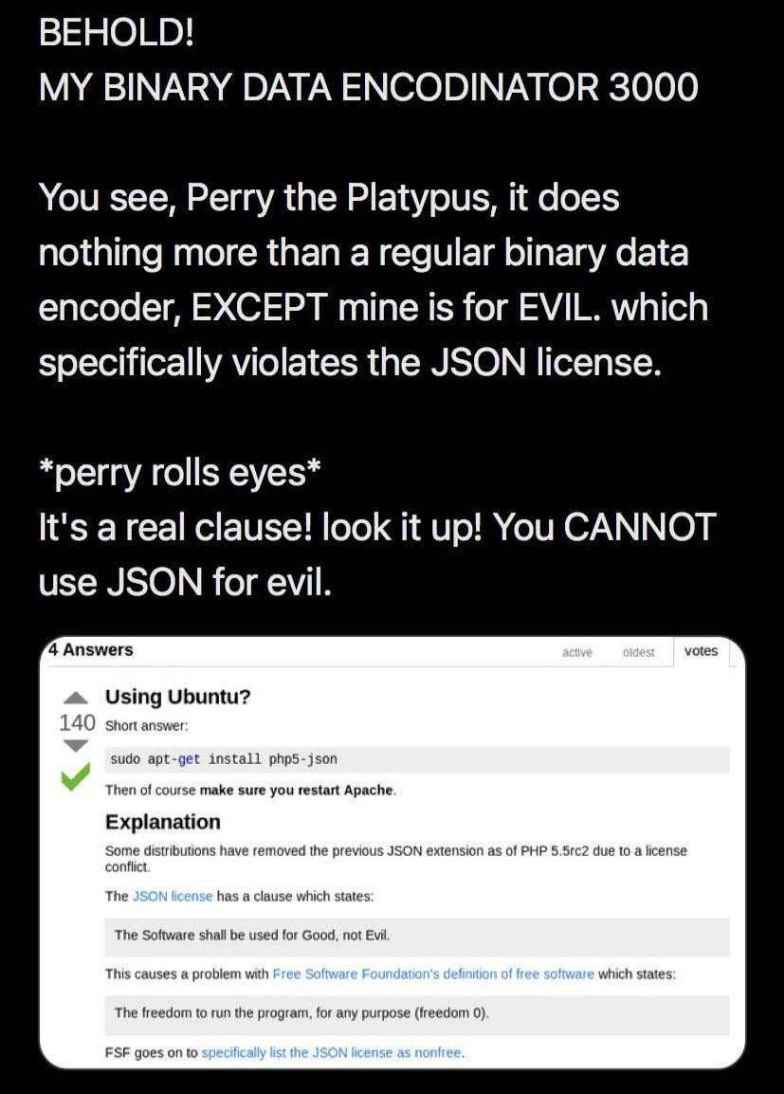
How does one address the paradox that, as JSON itself is evil, one cannot use it for evil?
(opinions may vary on the above; but it’s mine, so nyah nyah.)
It’s less evil than XML or YAML
YAML is evil.
Idk, I never used the weird advanced features of YAML, but the basics seems really nice for stuff you want people, especially non programmers, to edit. I generally default to YAML for config files.
XML is ok for complex docs where you have a detailed structure and relationships. JSON is good for simple objects. YAML is good for being something to switch to for the illusion of progress.
Meh. I just wish XML was easier to parse. I have to shuttle a lot of XML data back and forth. As far as I can tell, the only way to query the data is to download a whole engine to run a special query language, and that doesn’t really integrate into any of my workflows. JSON retains the hierarchy and is trivially parsed in almost any programming language. I bet a JSON file containing the exact same data would be much smaller also, since you don’t list each tag twice.
I still want someone to explain to me why XML even needs namespaces (which cause about 95% of all issues regarding XML).
There is a way to separate different XML structures, it’s called files.
XML is also tricky to parse because people forget it is for documents too. It’s basically like HTML. Mixed content elements are allowed.
<foo>hey <bar>there</bar> friend</foo>is valid XML. So iterating over elements is trickier than JSON (which is just key value pairs and arrays).There are parsing libraries, maybe not as many or as open, but they exist.
That’s kind of my point though. For being made specifically for the purpose of being machine readable, its kind of a pain in the ass to work with.
I want a command line utility where I can just
or in python
import xml with open("foo.xml", "r") as file: data = xml.load(file.read())That’s the amount of effort I want to put into parsing a data storage format.
It’s still using the lesser of 3 evils, we need a fourth human readable data interchange format.
"Problem: There are
34 standardsObligatory xkcd
>TOML has entered the channel
Any human-readable format compatible with JSON is inevitably going to be used as an interchange format…
The lesser of what?
Hmm, hard to argue with that :P